Many processes and events involve examining sets of elements and performing operations on them – such as joining the sets or discovering whether two elements belong to the same set or not. For example, we can talk about sets of objects, sets of individuals, sets of locations (checking that they belong to the same owner or buying and thus uniting multiple locations that previously belonged to different individuals), etc.
Let’s say, you have a set of N elements which are partitioned into further subsets, and you have to keep track of connectivity of each element in a particular subset or connectivity of subsets with each other. To do this operation efficiently, we can use Disjoint Set Data Structure.
The whole idea is how to select a good representative ‘parent’ item to represent a set. We need to ensure that all vertices in one set have one unique ‘representative’.
WHAT IS A DISJOINT SET?
A disjoint set is a group of sets where no item can be in more than one set. It is also called as Union-Find data structure as it supports union and find operations. Let us begin by defining them-
Find: It determines the set in which a particular element is present and returns the representative of that particular set. An item from the set acts as a “representative” of the set.
Union: It merges two different subsets into one single subset and representative of one set becomes the representative of the other.
HOW DOES UNION-FIND WORK?
We can determine if two elements are in the same subset or not by comparing the results of their find operations. If the two elements are in the same subset they have the same representative, else they belong to different subsets.
If union is called on two elements, we merge the two subsets which the two elements belong to.
BUILDING AN EFFICIENT DATA STRUCTURE!
The disjoint-set data structure takes advantage of tree structures where the disjoint sets form a forest of trees. The root of one tree is picked to be the representative for all its descendants.
In the following image, you can see the representation of such trees.
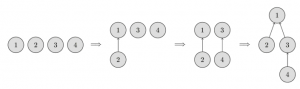
At the beginning every element starts as a single set, therefore each vertex is its own tree. Then we combine the set containing the element 1 and the set containing the element 2. Then we combine the set containing the element 3 and the set containing the element 4. And in the last step, we can the sets containing the elements 1 and 3 are merged.
IMPLEMENTATION
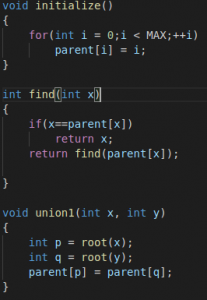
For the implementation, this means that we will have to maintain an array parent that stores a reference to its immediate ancestor in the tree.
Initially, there are N subsets containing a single element in each subset. Therefore, each element of the parent array (representing the subset containing that single element ) is initialized to itself. meaning that it is its own “ancestor”.
To combine two sets (operation union1(a, b)), we first find the representative of the set in which a is located and the representative of the set in which b is located. If the representatives are identical, that we have nothing to do, the sets are already merged. Otherwise, we can simply specify that one of the representatives is the parent of the other representative – thereby combining the two trees.
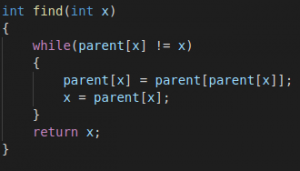
Finally the implementation of the find representative function (operation find(v)): we simply climb the ancestors of the vertex v until we reach the root, i.e. a vertex such that the reference to the ancestor leads to itself. This operation is easily implemented recursively.
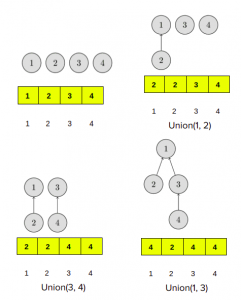
However, his implementation is inefficient. Trees can degenerate into long chains. In such cases, each call find(v) can take O(n) time.
Let us see if we can optimize it further to get nearly constant time.
PATH COMPRESSION OPTIMIZATION
This optimization is designed to speed up find(v).
When we call find(v) for some vertex v, we actually find the representative p for all vertices that we visit on the path between v and the actual representative p, by recursively calling for the parent of the vertices on the path. The trick is to make the paths for all those nodes shorter, by setting the parent of each visited vertex directly to p.
You can see the operation in the following image. On the left, there is a tree, and on the right side, there is the compressed tree after calling find(7), which shortens the paths for the visited nodes 7, 5, 3 and 2.
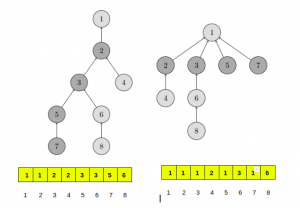
This simple modification of the operation already achieves the time complexity O(log N) per call on average.
TIME COMPLEXITY
When we use union-find with path compression it takes log * N for each Union-Find operation, where N is the number of elements in the set.
log *N is the iterative function which computes the number of times you have to take log of N till the value of N doesn’t reach to 1. log*N is much better than log N, as its value reaches at most up to 5 in the real world.
APPLICATION
1) As explained above, Union-Find is used to determine the connected components in a graph. We can determine whether two nodes are in the same connected component or not in the graph. We can also determine that by adding an edge between 2 nodes whether it leads to a cycle in the graph or not.
We learned that we can reduce its complexity to a very optimum level, so in the case of very large and dense graphs, we can use this data structure.
2) It is used to determine the cycles in the graph. In the Kruskal’s Algorithm, Union Find Data Structure is used as a subroutine to find the cycles in the graph, which helps in finding the minimum spanning tree.
PRACTICE PROBLEMS


