
There are 2 hard problems in computer science: cache invalidation, naming things, and off-by-1 errors.
– Leon Bambrick
We are all aware of the word cache. It is a high speed hardware that stores data and has low storage capacity. The data that is stored in the cache is stored as a result of being frequently accessed or are duplicated copies of data stored in another location. Caching essentially makes future referencing quicker. This improves the performance as cache access time is less (being closer to the server) than database.
The cache is structured around keys and values – there’s a cached entry for each key. When you want to load something from the database, you first check whether the cache doesn’t have an entry with that key (based on the ID of your database record, for example). If a key exists in the cache, you don’t do a database query.
It all looks so easy. So, why is there a lot of buzz about it??
Assume that we have only one global cache for all servers and there is a new video launched on YouTube. Suddenly, it’s getting a lot of hits. As a result, when a user requests this video, it will be accessed from the cache rather than the database. Since cache memory is small, it cannot take a lot of load at a time. As a result, it will crash. Each request again goes to the database. This is where distributed cache comes into picture.
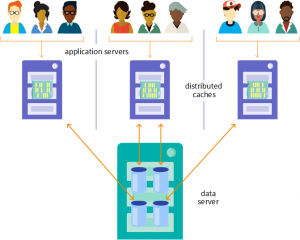
As the name suggests, the data is distributed across many more than one cache unit(or a node). It may happen that 5 cache units are serving a request to a user at a time. As a result, your data request load gets divided between all cache unit and you achieve linear growth in transnational capacity as you increase cache units in the cluster. So, when there is a lot of requests for the same data, the load is distributed among many cache units. A distributed cache runs as an independent processes across multiple units and therefore failure of a single unit does not result in a complete failure of the cache
Being distributed doesn’t totally imply that each cache unit will have a different set of data cached. If this applies and one of the cache unit goes down, all of its cached data will be lost. Typically, Distributed caching system are very reliable using replication support. If one or more unit goes down and you had the replication turned on then there will be no data loss or downtime. The replicated data of that unit is automatically made available from the surviving server node. One more thing to worry about distributed cache is data coherency over all cache with replicated data.
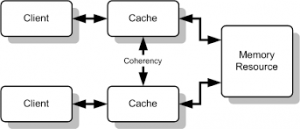
Assume that Psy updates his “Gangnam Style” video and this data is updated in database but some caches have the same old video stored. This will lead to some users still watching the same old video ?. To ensure this doesn’t happen when you do an update, you also update the cache entry, which the caching solution propagates in order to make the cache coherent. Note that if you do manual updates directly in the database, the cache will have stale data. So cache invalidations(updation and deletions) for dynamic data is really really important.
I hope after reading this you may have a clear picture in mind about the distributed caches in servers and how they make your searches faster while working with each other.
Happy Reading ?



Comments
I’m really enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit
more often. Did you hire out a developer to
create your theme? Outstanding work! http://jaxtonaqhda.gratisblog.biz/2020/12/22/are-really-remarkable-training-finals-extreme-to-desire/ http://hadassahmjsafl3.Mee.nu/?entry=3131181 http://charleyrtchxbe06.mee.nu/?entry=3131122
Here is my blog: discount hockey jerseys China