
Support vector classifiers come under the supervised learning category of machine learning. In simple terms, if you train the classifier with some data along with the corresponding labels, it will try to label new examples correctly. SVM does this by constructing a hyperplane which separates the classes on either side (binary classification).
This blog is a walk-through of how you can enhance your SVM for spam classification to the next level 🙂 . I don’t think that you need any pre-requisite but still it will be easy for you to understand if you have a brief knowledge of SVM. If you have any suggestions, do let me know. If you think there are better methods, then also do let me know 🙂
Code description
This is not a walkthrough of the code but rather a do this, don’t do that part. Breaking the algorithm down into sections is always beneficial, so let’s do that first.
- Data cleaning
- Feature extraction
- Parameter tuning
- Metric selection
Data cleaning: Stemming vs Lemmatization

When you have a huge amount of data, it’s highly recommended to clean your data up. Basically, you are trying to remove the garbage and to keep the gold. In mail classification, you can generally start with lowering the case, punctuation removal, filtering the headers of the mail and removing stop words. But even after all of this, we are left with a lot of words. This is where stemming and lemmatization comes in.
Words like study, studies, studying, studied more or less have the same meaning, so if we can just replace all of them with the word study, we’re done. Stemming and Lemmatization both have this exact mindset but the results might differ, because Lemmatization will always return a root word which actually has a meaning whereas the Stemming won’t always. For eg “scientific” is reduced to “scientif” by Porter stemmer which apparently has no meaning whereas lemmatization won’t alter it, but this comes at a cost of speed as lemmatizers have to look up a dictionary of words and pay attention to the part of speech (pos tagging) while deriving the root form.
Feature extraction: TFIDF vs Count vectorizer

As we all know, machines are better with numbers and humans with words, before the data is fed into the classifier it has to be converted into a format which is machine compatible.
CountVectorizer is a great way to tokenize the text and represent each message in the form of a vector. Let a message’s vector be V[], if the word V[i] is present in the message then V[i]=1 otherwise zero. It is also a great way to count the frequency of the words which can be used as a feature. But, it’s pretty straightforward and we know we can do better.
TFIDF tells us how important a word is to that message with respect to the corpus. Consider three words “with” “Virat Kohli” “Floccinaucinihilipilification”. We can consider their frequencies to be 100,10 and 1. These are the Term frequencies. Although “with” appears a lot of times, it hardly tells us anything about the document whereas the presence of “Virat Kohli” indicates cricket, hence should be given higher importance. Taking the inverse solves the problem ( Eureka! ), now we have 0.01,0.1 and 1. But “Floccinaucinihilipilification” has a higher priority but is a useless word hence reciprocating won’t help 🙁
To solve this for each word, we calculate log(total messages/messages having the word). This is Inverse document frequency. Product of TF and IDF is the solution. Try it out if you have any doubts 🙂
Parameter tuning: Cross validation+Grid search vs train test split
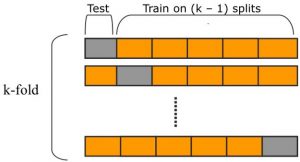
Almost all of us have done the 70–30 train test split and it works Hurrah!, but what if the features present in the 30% of your dataset is not learned by the model? Yes, the random state helps but not always. Hence the accuracy returned will not be absolute.
Suppose if we divide the corpus into 10 parts, then select 1 part for testing and the other 9 for training and repeat this for all the parts. In this manner, the impact of feature dominance will be normalized and the accuracy can be trusted. After we are done with all this, parameter tuning can be easily handled by Grid search. You can input a dict of parameter along with their ranges and get the best_params_ as the result.
Metric selection: Accuracy, Precision, and Recall
Accuracy is definitely the first metric that crosses anyone’s mind but unfortunately, that’s not enough. In email classification reducing the false positive should be our biggest goal as we don’t want our important mail to land in junk, whereas a few spams in our inbox won’t hurt. To control this we have precision and recall which are calculated as,
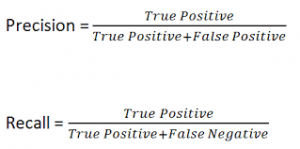
Having high precision will lead to lesser false positive and hence better realization of our objective. Sometimes having better recall is expected hence a new term comes into play, F1 score which tries to bring both recall and precision into the picture.
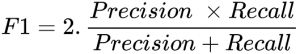
Other notable metrics are confusion matrix, ROC AUC and PR AUC along with Cohen’s Kappa, all which require individual articles 🙂
Conclusion
I hope this article helped you to improve your SVM model in general. To make it more generic you can apply it to almost all the ML algorithms that are present !. Also I have to mention this 😛 , these are some of the techniques that I am using to develop a statistical classifier plugin for Apache Spamassassin during Google Summer of Code 2019.
Until next time, happy reading 😀



Comments
Spot on with this write-up, I honestly believe this website needs much more attention.
I’ll probably be returning to read through more, thanks for the info!