
“Good generalization on complex tasks can be obtained by designing a network architecture that contains a certain amount of a priori knowledge about the task”
Prerequisites: familiarity with the CNN architecture; basic understanding of Time-frequency trade-off.
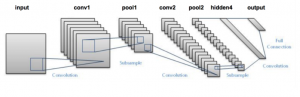
The Convolutional Neural Network(CNN) or ConvNet has a structure similar to what is shown in Figure 1. Such a hierarchical structure was first proposed by Fukushima in “Neocognitron: A Hierarchical Neural Network Capable of Visual Pattern Recognition”, 1988. He proposed this model based on how the human brain processes images. In various studies, it was found that while processing images, neurons respond selectively to local features. They also noticed that there exist cells which respond to certain shapes and figures like triangles, squares, and even human faces. Later, in the 1989, Yann LeCun(Turing Award winner 2018 along with Yoshua Bengio and Geoffrey Hinton) and his team proposed a backpropagation algorithm and applied a CNN to classify handwritten digits with 95%(102 mistakes) accuracy on validation set, which was the new state-of-the-art at that time (Get the accuracy if you can). After this, further improvements were made to CNNs and state-of-the-art results were reported in many recognition tasks.
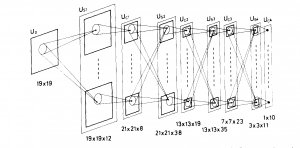
Ideas like sparse interactions, parameter sharing, and equivariant representations make CNN’s better choice over traditional multilayer perceptrons. Convolutional Neural Networks are very famous for their application in Image & Video recognition, Image Analysis & Classification, etc. Another application of CNN is in audio processing. Audio processing using CNN’s can be achieved in two different ways.
- Using Mel Spectrogram. – As Mel Spectrogram is an image, 2D convolution can be applied for processing.
- Using the raw signal. – Applying 1D convolution on a raw audio signal.
The problem of Time-frequency trade-off
Though we can apply CNN with 1D convolution layers on the raw signal, this would not capture the whole essence of the signal. Uncertainty Principle in Signal processing(Gabor Limit) gives us a relation between the kernel size used and the resulting time-frequency resolution. If one uses a wide kernel, one achieves good frequency resolution at the cost of temporal resolution, while a narrow kernel has the opposite trade-off.
The Multi-temporal architecture
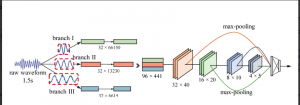
Tackling this problem leads us to the architecture of Multi-temporal CNN. This architecture consists of multiple CNN branches, each one convolving the audio signal with kernels of different sizes. The outputs of these individual branches are concatenated. This branching and concatenation can be repeated. Finally, a fully connected layer and activation layer are added. This ensures that different time-frequency resolutions of the input are captured.
Branching in CNN is not uncommon. Different branches are often used for classifying on a various basis or recognizing different types of objects. Example of a branched CNN used for CIFAR-100 dataset is given in figure 3. The multi-temporal architecture is a special type of branching, where the concatenation yields a very rich feature map. The multi-temporal approach has given state of the art results in applications like Audio Scene Classification(ASC). Even though Multi-temporal architectures seem very effective, they are not very popular.
(a)
GoogLeNet
In ImageNet Large-Scale Visual Recognition Challenge 2014(ILSVRC 14), Google engineers competed with the codename GoogLeNet. Their model was a deep convolutional neural network architecture codenamed Inception, which was responsible for setting the new state of the art in 2014. This structure actually has branching with different kernel sizes and concatenation similar to the multi-temporal CNN architecture.

Knowing the classification task at hand, the model should be designed according to the task requirements and the nature of the data. Multi-temporal CNN architecture is very effective if raw audio is the data, and time-frequency trade-off plays a role in the task at hand. In the same way, any task can be solved with better generalization by asking the basic questions regarding the task.
References
CNN Architectures: LeNet, AlexNet, VGG, GoogLeNet, ResNet and more: https://medium.com/@sidereal/cnns-architectures-lenet-alexnet-vgg-googlenet-resnet-and-more-666091488df5
Fukushima 1988: http://vision.stanford.edu/teaching/cs131_fall1415/lectures/Fukushima1988.pdf
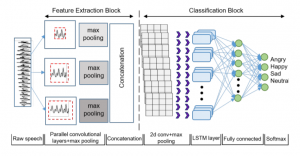
Direct Modelling of Speech Emotion from Raw Speech: https://arxiv.org/pdf/1904.03833
Branched CNN: https://arxiv.org/pdf/1709.09890.pdf
Going deeper with convolutions: https://arxiv.org/pdf/1409.4842.pdf


